

generative ai
research
Embeddings and Context Loading: A Comparative Study for Generative AI

In short, embeddings are vector representations of data that capture their meaning and context. Context loading is a technique that uses generative AI to load relevant and personalized content for the user. Both methods are essential for creating high-quality and diverse content with generative AI models.
In this study, we compare and contrast supervised and unsupervised learning approaches for generating embeddings and context loading. We also provide examples and evaluations of generative AI applications that use these methods.
How Do Embeddings Work at a Simple Level?
Embeddings work by converting words or entities into numerical representations that capture their semantic relationships. These numerical representations are stored in a vector database. When a query is submitted, it is also converted into a vector. A similarity search, often using cosine similarity, is then performed to find the most relevant text or ideas from the vector database that match the query. This allows AI models, like language models, to effectively understand and process language.
Modelling Text Semantically
Common embedding models, such as Word2Vec and GloVe, learn to represent words as dense vectors in a high-dimensional space where the geometric distance between vectors corresponds to their semantic similarity. For instance, in a simplified scenario, let's consider a Word2Vec model trained on a corpus of text containing the sentence "always something you can do" along with many other sentences. The model learns to represent each word in this sentence as a vector in a continuous vector space.
After training, the model might assign the following vectors to the words in the sentence:
"always": [0.2, -0.1, 0.5]
"something": [0.3, 0.4, -0.2]
"you": [-0.3, 0.1, 0.6]
"can": [-0.1, -0.5, 0.3]
"do": [0.4, 0.2, 0.1]

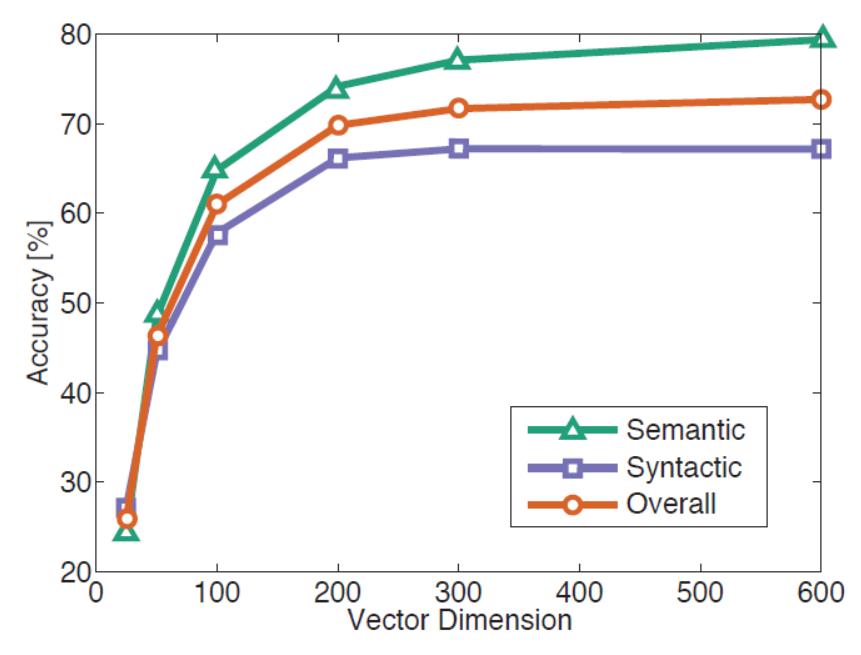
The values in the array represent the coordinates of the word vectors in the vector space. Each value corresponds to a dimension in the vector space. In this example, we're using a simplified vector space with three dimensions for ease of understanding, but in practice, these spaces can have hundreds or even thousands of dimensions. For example, the dimensionality of Word2Vec embeddings is often chosen to be in the range of 50 to 300 dimensions. The diagram on the right (below on mobile) showcases the diminishing returns from using more than 300 parameters in the vector embeddings.
Vector Databases and Similarity Searches
We have seen how the embedding vectors are created but how are they used to provide context to LLM’s such as the GPT models or even Llama LLM? The main way of doing this is doing a similarity search on the input prompt to accurately source the relevant information to the user’s query. This is often referred to as the retrieval process.
The tremendous benefit of having these embedding vectors is that we can perform all sorts of operations on them. They are much more easy to manipulate and easier for the computer to understand compared to their string form. By housing all these vector embeddings in a database, we create a searchable index to provide to our LLM.
When a user inputs a query to the LLM, the query is converted to an embedding which can then be matched to the relevant embedding vectors in our vector database. The closest matching vectors are calculated by minimizing a distance function such as the cosine similarity function.
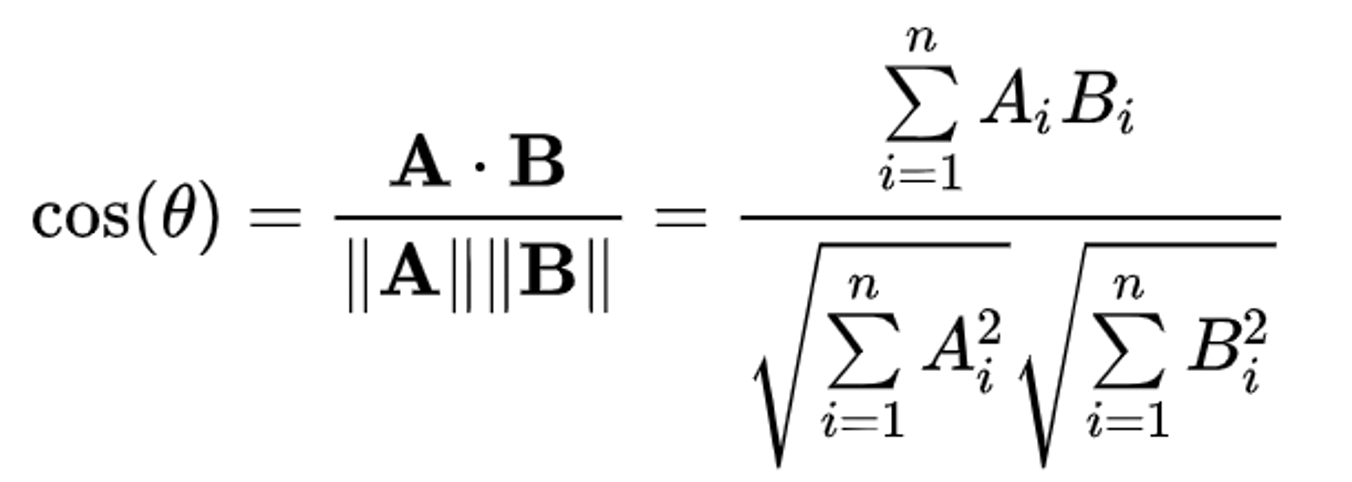
Once we have grabbed the relevant text, we can inject this text into our prompts. Langchain probably has the biggest library of retrieval tools in the generative AI space right now for this. A simple retrieval chain can be set up using a vector database that does what we explained above. In short, it would modify user prompts by sourcing additional and relevant information from the database before feeding the adjusted prompt into the LLM to generate a response. Its a marvel of prompt engineering!

Is there an easier way? - Context Loading
Context loading as the name implies, refers to the approach of loading the context parameter with all the relevant text you made need for a task.
This approach has not always been as feasible as it is today due to the traditionally smaller content windows. For instance, the first GPT models had a context window of only 512 tokens, limiting the amount of text they could consider for generating responses. However, advancements in model architectures and computational resources have expanded the context windows, allowing for more extensive context loading.

The context window of GPT-4-Turbo is capped at 128,000 tokens, a truly remarkable feat. To put this into perspective, it's equivalent to processing an entire novel or multiple lengthy articles in a single pass. This expanded capacity allows the model to consider a vast amount of context when generating responses, resulting in more comprehensive and nuanced outputs. With such an extensive context window, GPT-4-Turbo has the capability to capture intricate details, understand complex narratives, and provide highly informed and contextually relevant responses across a wide range of tasks and domains. OpenAI are not the only company to have a model with this capacity, Mistral and Anthropic are said to have models with similar context sizes.
How Effective is It?
In our own experience, it is very effective for repetitive and static tasks such as retrieving specific names or descriptions from our input context. We formerly used it as part of Theme Explorer V1’s software since we initially had limited potential training data.
The ability to quickly and efficiently draw information from the context window can be used in a similar way to the embeddings approach and with the increasingly big context windows we have access to now, you may be able to get away with it for certain tasks.
The main issue is the ability for the entire context window to be considered when the LLM attempts to generate a response. Hallucinations and inaccuracies of information are common when trying utilize a large context window. A way of testing the effectiveness in a large context window is the ‘needle in haystack’ benchmark.
Research suggests that even the most powerful models fail to recall certain queries or information when the content in a context window exceeds a certain point (<64k tokens in the test). In particular, the LLM was able to retrieve the information when it was near the beginning or the very end which indicates an inherent bias for text at these positions.

We noticed a similar feature when using context loading for our image generation tool. Initially, the tool would only extract and use text from the very beginning of the context window limiting its ability to create unique art. This has since been fixed using randomisation and eventual move to embeddings to store our context.
